
1. 始める前に
スマートホームをデバッグするの Codelab で説明したとおり、スマートホーム プロジェクトには指標とログを公開しています。これらの指標は、スマートホーム アクションに問題があるかどうかを識別する際に役立ちます。またログは、そうした問題を解決するための詳細を確認するのに便利です。
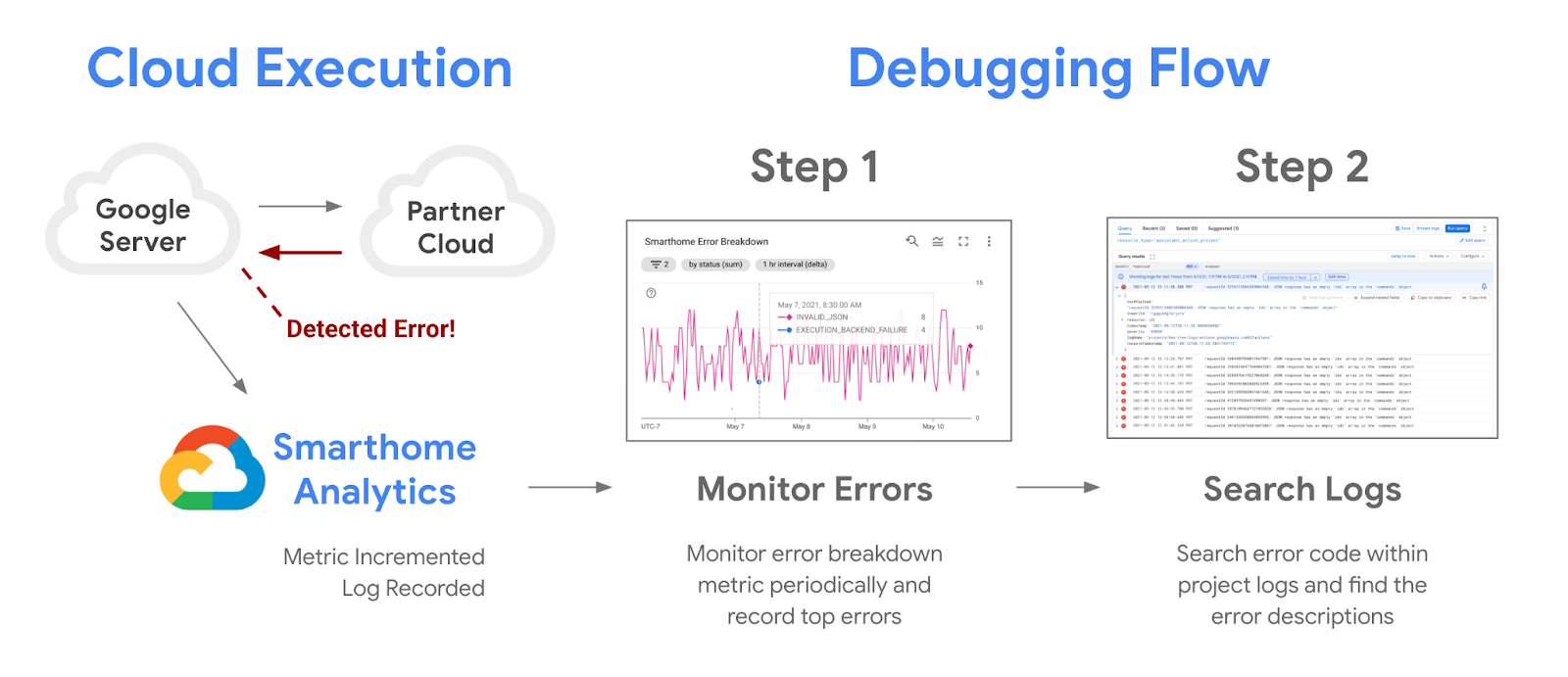
プロジェクトに提供された指標を使用してアラートを設定すると、障害を自動的にモニタリングし、サービス停止時に通知を受け取ることができます。この Codelab では、プロジェクトの中断をハイライトする信頼度指標を公開します。この指標については、Google Cloud で利用できる他のすべてのアラート ツールとともに説明します。
前提条件
- Works with スマートホームの統合が済んでいる。
- スマートホームをデバッグするの Codelab を完了している。
学習内容
- プロジェクトのパフォーマンスの問題とサービスの中断をモニタリングする方法。
- しきい値ベースのアラートを作成し、中断中に通知を受け取る方法。
- プロジェクトに提供された信頼度指標を使用して停止を検出する方法。
2. パフォーマンスのモニタリング
Google Home エコシステムとの統合を成功させるには、パフォーマンスのモニタリングが不可欠です。Google は、Google Cloud でスマートホーム デベロッパー向けに一連のモニタリング ツールを提供しています。これらのツールを使用すると、プロジェクトのパフォーマンスを把握できます。
ダッシュボードへのアクセス
データにアクセスする最初の手順は、Google Cloud コンソールにログインして [オペレーション] > [モニタリング] > [ダッシュボード] に移動し、Google Home ダッシュボードを確認することです。利用可能なダッシュボードが多数表示されます。スマートホームのダッシュボードには、Google Home Analytics という接頭辞が付いています。
統合タイプごとに個別のダッシュボードを作成しました。クラウド、ローカル、Matter の統合には独自のダッシュボードがあり、カメラ ストリーミング プロトコルのデータはカメラ品質ダッシュボードで提供されます。これらのダッシュボードにデータが表示されるのは、対応するタイプの統合と、リクエストを処理する機能するプロジェクトがある場合のみです。
これらのダッシュボードのいずれかを開くと、次のようなビューが表示されます。
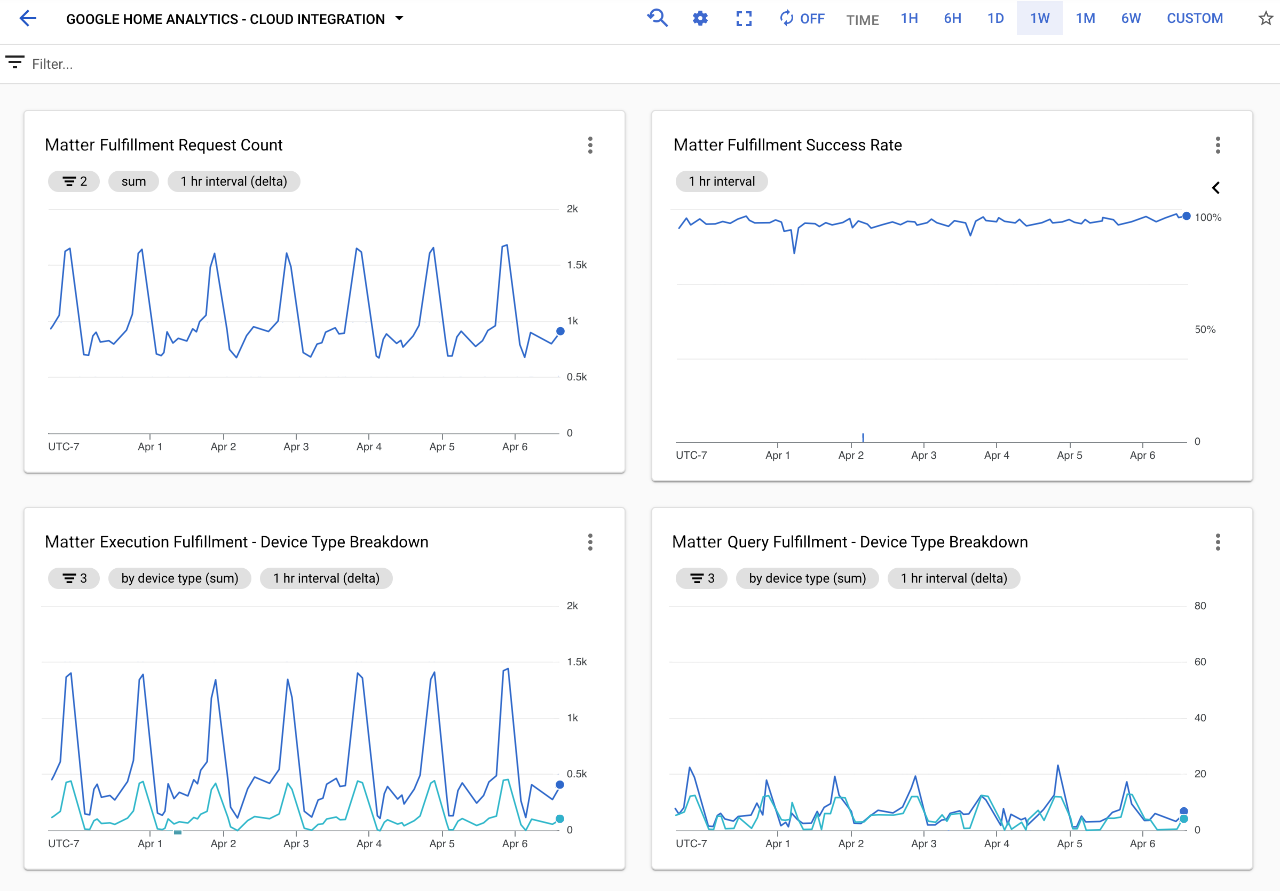
ダッシュボードには、プロジェクトで処理されたリクエストの詳細を示すさまざまなグラフが表示されます。統合ダッシュボードには、プロジェクトで処理されたリクエストの合計数を示すグラフ、その統合タイプの成功率を示すグラフ、関連するデバイスタイプと特性を示す複数のグラフが表示されます。
スマートホーム アクションのパフォーマンスを評価するうえで重要なグラフは次の 3 つです。

通常、サービス停止中は成功率が低下し、エラーの内訳グラフではエラーの割合が増加します。実行成功率をモニタリングすると、停止に気づきやすくなります。また、エラーの内訳で上位のエラーを確認すると、デバッグに役立ちます。停止中にレイテンシの上昇傾向が見られることもあります。これは、リクエスト レイテンシ グラフで確認できます。
Google Home Analytics ダッシュボードに表示されるグラフを含むデフォルトのビューは、スマートホーム指標データを使用してプロジェクト用に作成されたビューです。Metrics Explorer を使用して、同じ基盤となる指標から独自のグラフを作成し、カスタム ダッシュボードに保存することもできます。
Metrics Explorer
Metrics Explorer は、プロジェクトのデータセットの断面を可視化するツールです。このツールには、Google Cloud コンソールで [オペレーション] > [モニタリング] > [Metrics Explorer] に移動してアクセスできます。
Google Cloud には、スマートホームに関連しないものも含め、さまざまな指標がすぐに使用できます。スマートホーム用に提供される指標は「actions.googleapis.com/smarthome_action/...」リソースに一覧表示されています。指標選択ボックスに「smarthome」と入力すると、簡単に検索できます。
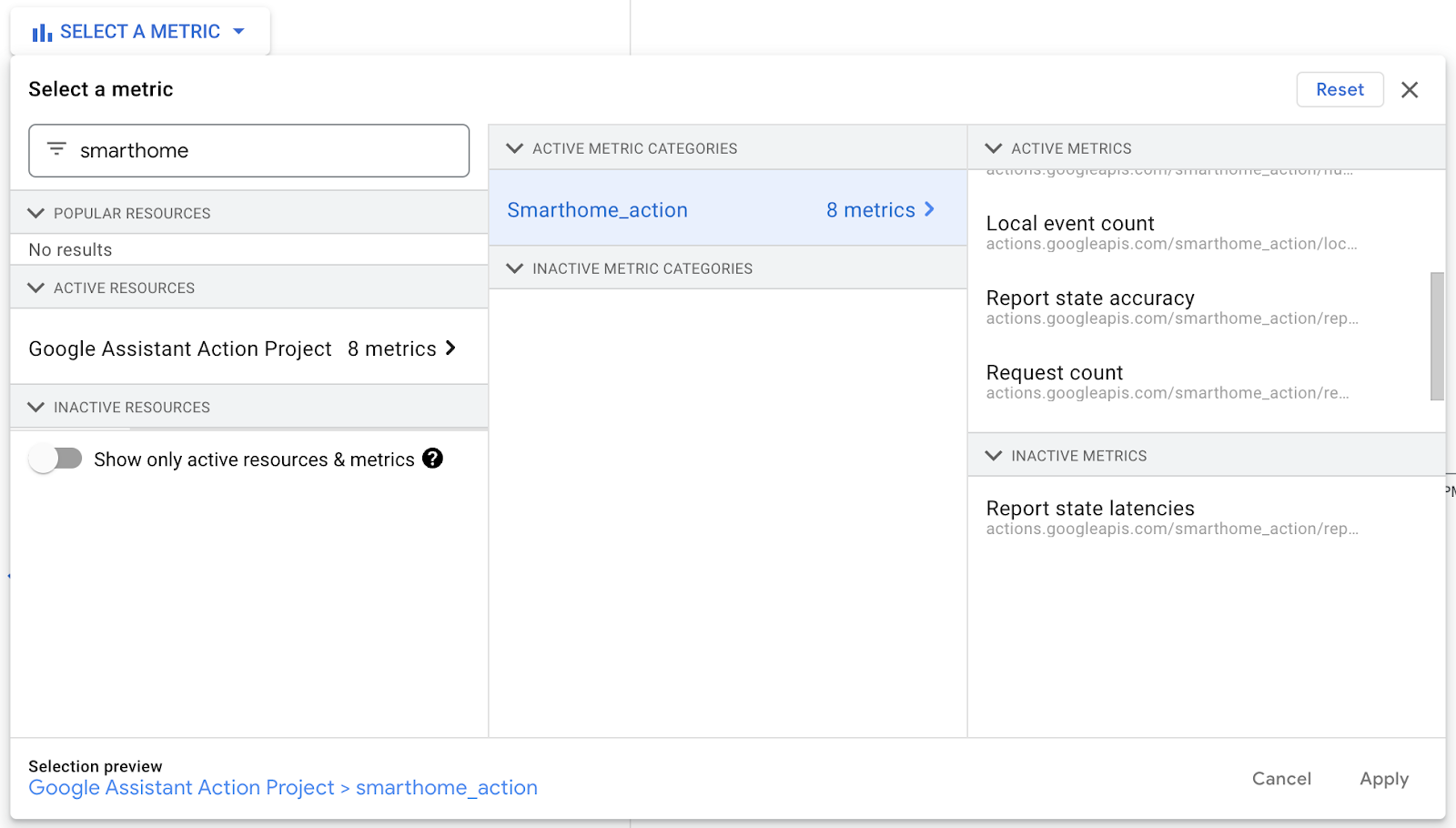
「smarthome」を検索すると、プロジェクトに提供されるすべてのスマートホーム指標が表示されます。各指標の詳細については、ドキュメントの Monitoring ページと Logging ページをご覧ください。
プロジェクトのモニタリングに関しては、最も簡単な指標はリクエスト数指標(デルタ指標)です。この指標は、ユーザーが開始したスマートホームの実行ごとにエントリを記録し、実行に関連するデバイスタイプ、トレイト、実行タイプ、結果を示すステータス フィールドなどのフィールドを記録します。
この指標を選択すると、次のような各データバケットを示す画面が表示されます。
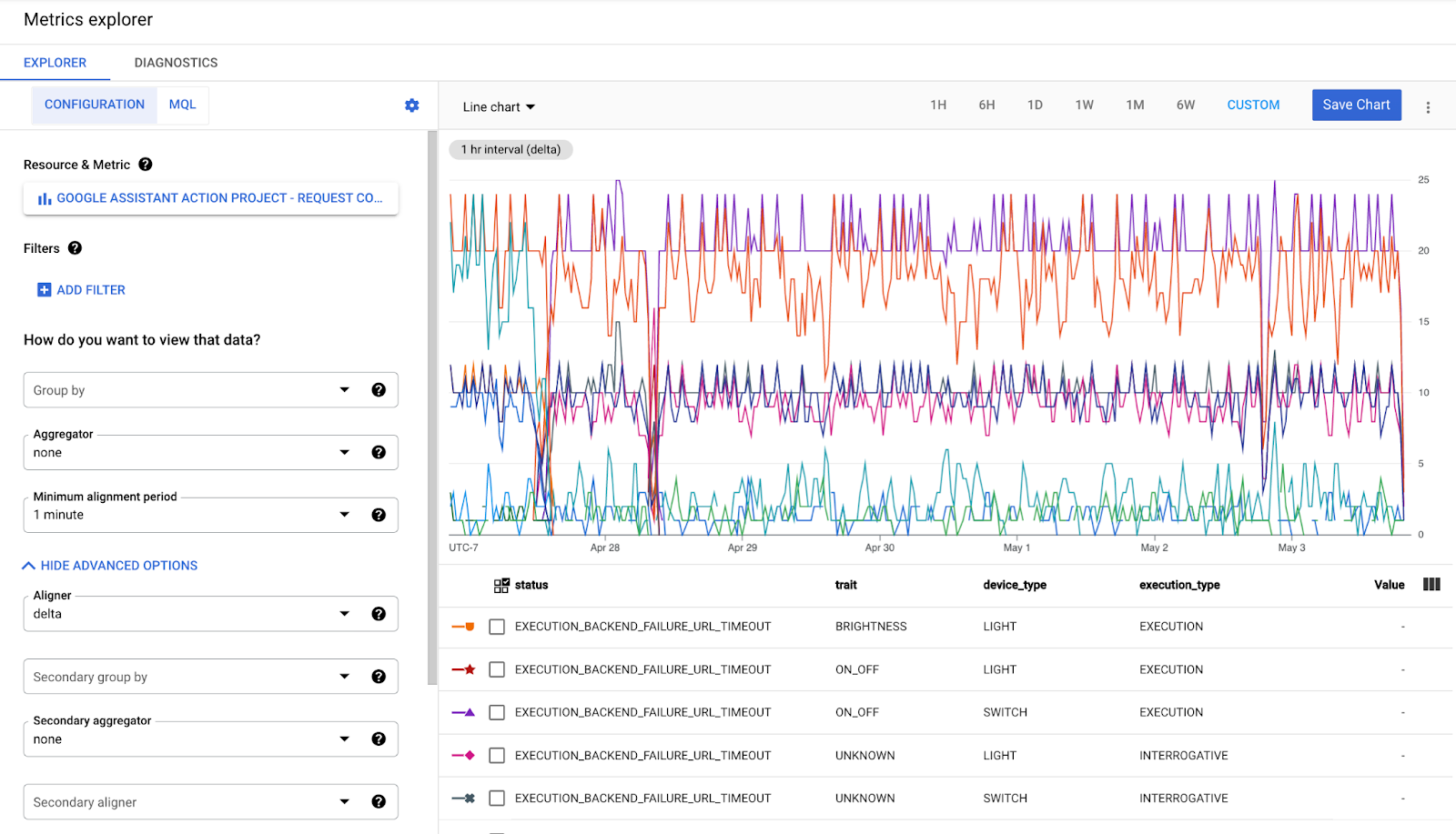
基本的に、この指標に存在するデータラベルの組み合わせごとに、前の時間間隔と現在の時間間隔の間の変化(デルタ)を記録するバケットが存在します。これらのバケットをグループ化または除外して、必要なビューデータのスライスを取得できます。また、データはアライメント関数(DELTA、MEAN、MEDIAN、SUM)を使用して、選択した時間間隔に調整されます。特に必要がない限り、通常はデルタ指標でデルタ アライメントを使用します。
Google Home Analytics ダッシュボードで使用可能なグラフのほとんどは、Metrics Explorer を使用して作成できます。また、作成したグラフはカスタム ダッシュボードに保存して、後でアクセスすることもできます。比率グラフなどのより複雑なビューを実現するには、MQL(Monitoring Query Language)を使用する必要があります。
3. 成功指標
統合の成功をトラッキングする際は、リクエスト数の指標から計算された成功率をベースライン指標として使用するか、より専門的なアプローチとして成功信頼度を使用できます。
成功率
成功率は、すべてのリクエストに対する成功したリクエストの数を割って、すべての統合について計算されます。Google Home アナリティクス ダッシュボードの [フルフィルメント成功率] グラフからアクセスできます。
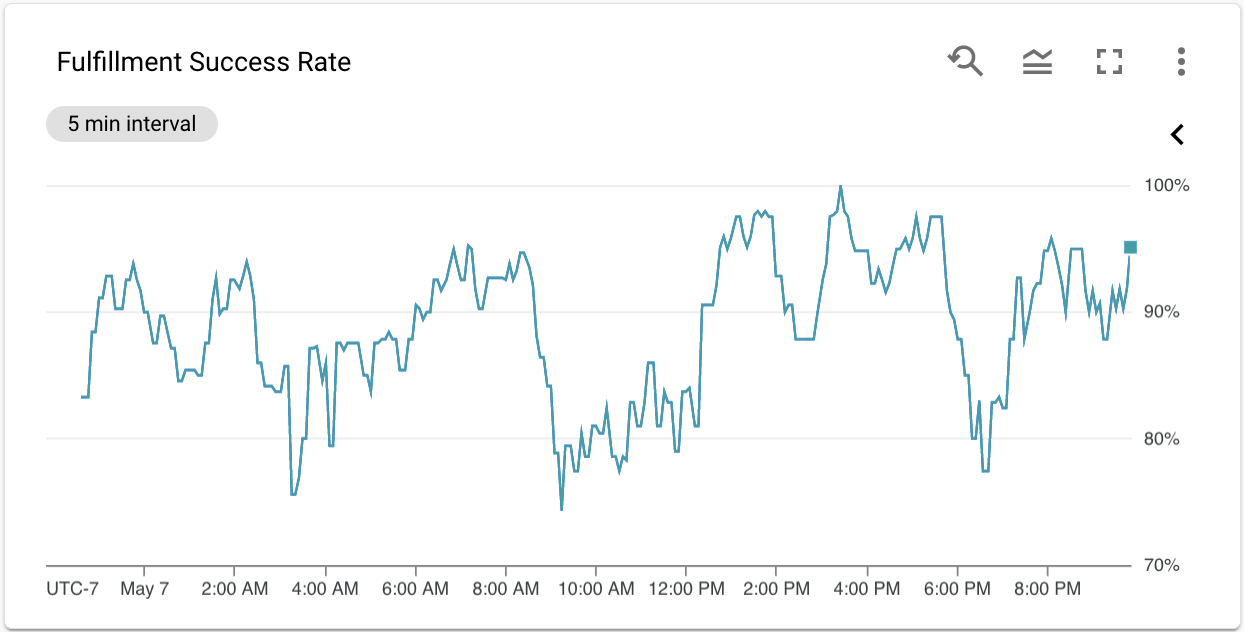
履行成功率のグラフは、プロジェクトのパフォーマンスをモニタリングするうえで非常に便利ですが、カスタム ダッシュボードの作成やアラートの設定にはあまり役に立ちません。成功率はリクエスト数の指標から導出されるもので、それ自体が指標ではないため、いずれかの機能で使用するには、Metrics Explorer で MQL(Monitoring Query Language)を使用して再作成する必要があります。
また、プロジェクトのパフォーマンスの低下を追跡するには、より専門的なアプローチが必要だと考えています。そのため、現在の履行成功率が過去の基準値からどの程度逸脱しているかに基づいて変化する信頼度指標を作成しました。
信頼度指標
プロジェクトでは、さまざまな形態や規模の停止が発生する可能性があります。数時間続くこともあれば、数分で終わることもあり、特定が難しい場合があります。このため、プロジェクトに信頼度指標を作成しました。この指標は、過去のパフォーマンスに基づいて信頼性を予測するための正規化された値を提供します。信頼度指標にアクセスするには、Metrics Explorer で「smarthome」を検索し、[Execution success confidence] を選択します。
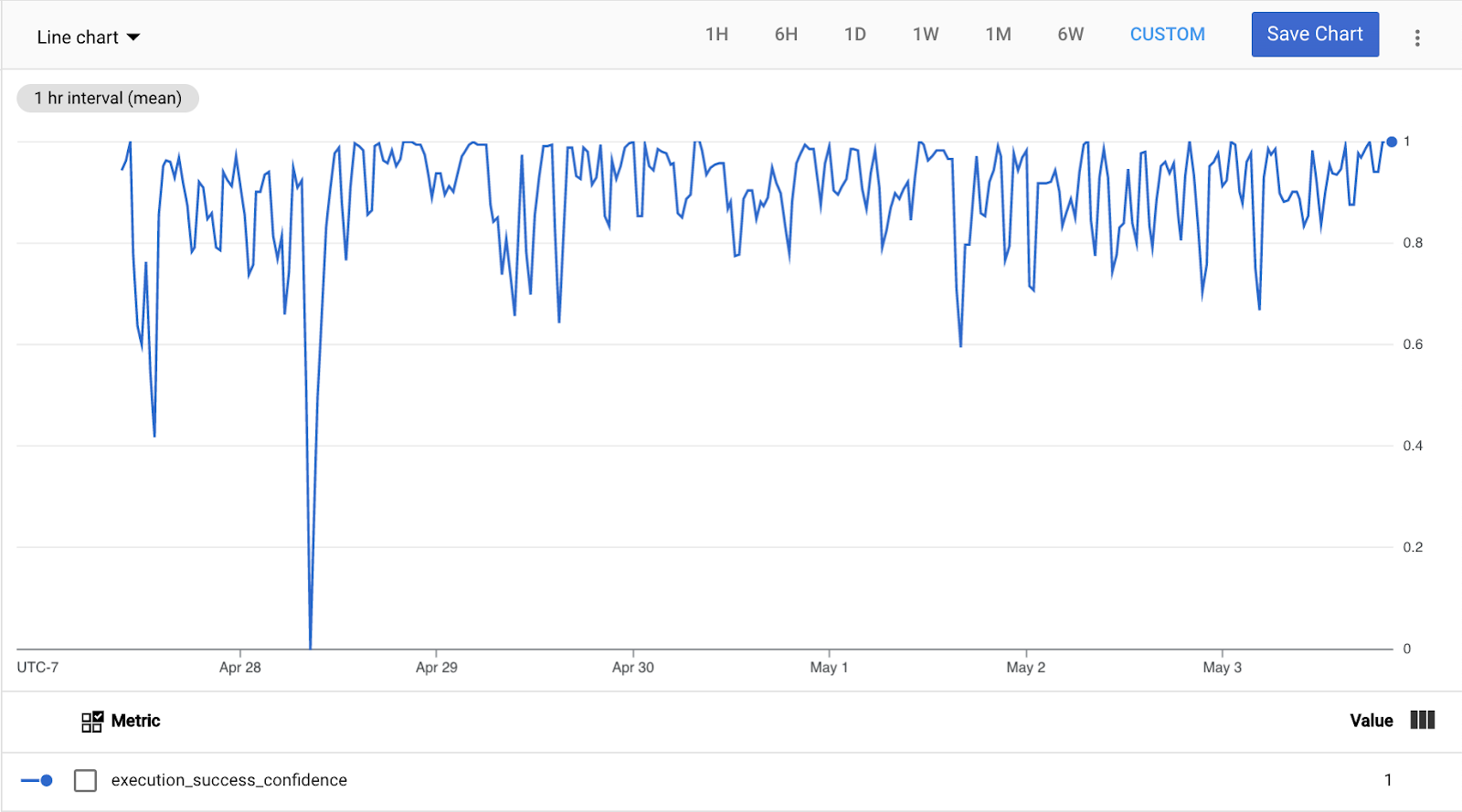
スマートホーム統合のパフォーマンスが過去のパフォーマンス(7 日間の平均)と同等以上の場合、この指標は最大値(1.0)を出力します。成功率が 4 標準偏差(7 日間で計算)を超えて変動すると、この指標は最小値(0.0)を出力します。標準偏差が小さすぎる場合(2.5% 未満)、この指標は成功率が 10% 低下したときの値を 0.0 とします。
中間的なケースでは、この指標は 1.0(停止がないと完全に確信している)から 0.0(停止があると最大限に確信している)の間の値を提供します。
そのため、アラートを設定する(次のセクションで説明)際は、しきい値として 0.5 の値を基準にすることをおすすめします。これは、2 標準偏差または 5% の減少のいずれか大きい方に対応します。
4. アラートの設定
次のステップでは、前のセクションで学習した内容をすべて使用して、プロジェクトのアラートを設定します。
アラート ポリシーを作成する
Google Cloud での自動アラートは、アラート ポリシーで設定します。アラート ポリシーには、サイドメニューの [オペレーション] > [モニタリング] > [アラート] タブからアクセスできます。[+CREATE POLICY] オプションを選択して、新しいアラート ポリシーを作成できます。このオプションを選択すると、アラート ポリシーの作成画面が表示されます。
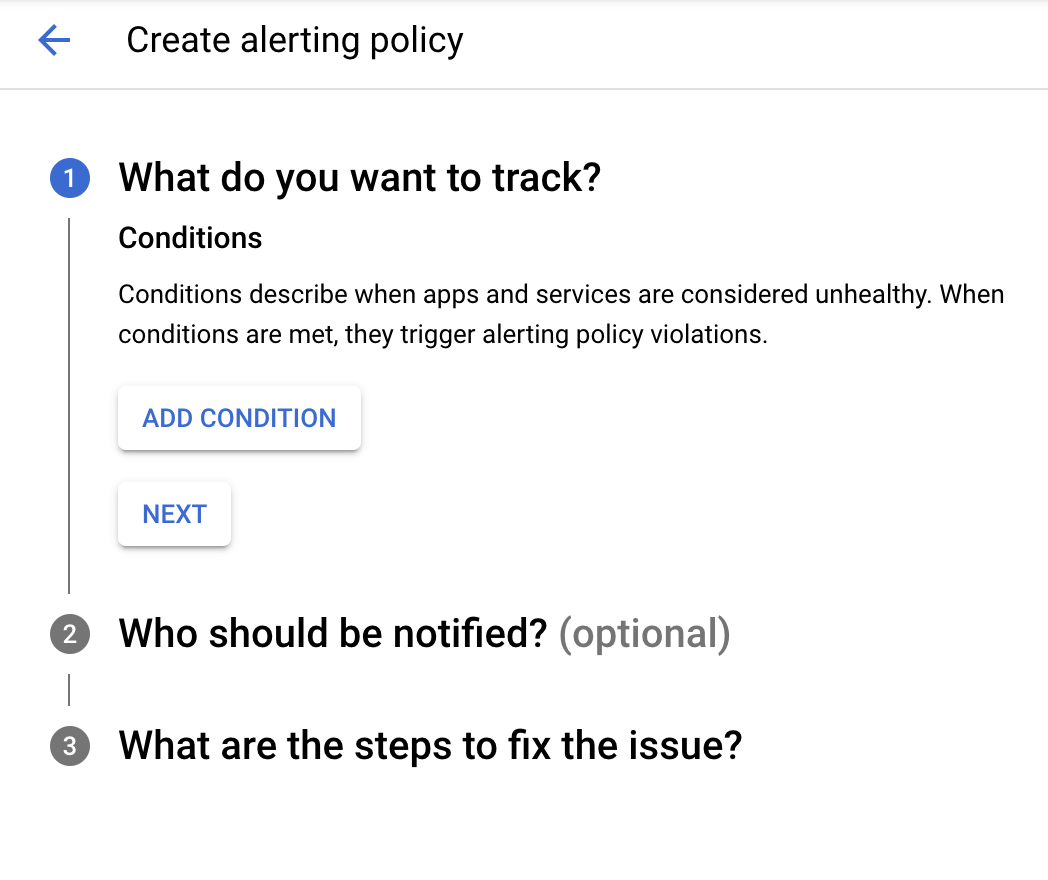
アラート ポリシーの作成は、次の 3 つの部分で構成されています。まず、条件を追加して、追跡する内容を決定する必要があります。[ADD CONDITION] ボタンを押すと、Metrics Explorer と同様のウィンドウが表示されます。このウィンドウには、条件を構成するための追加のコントロールがあります。
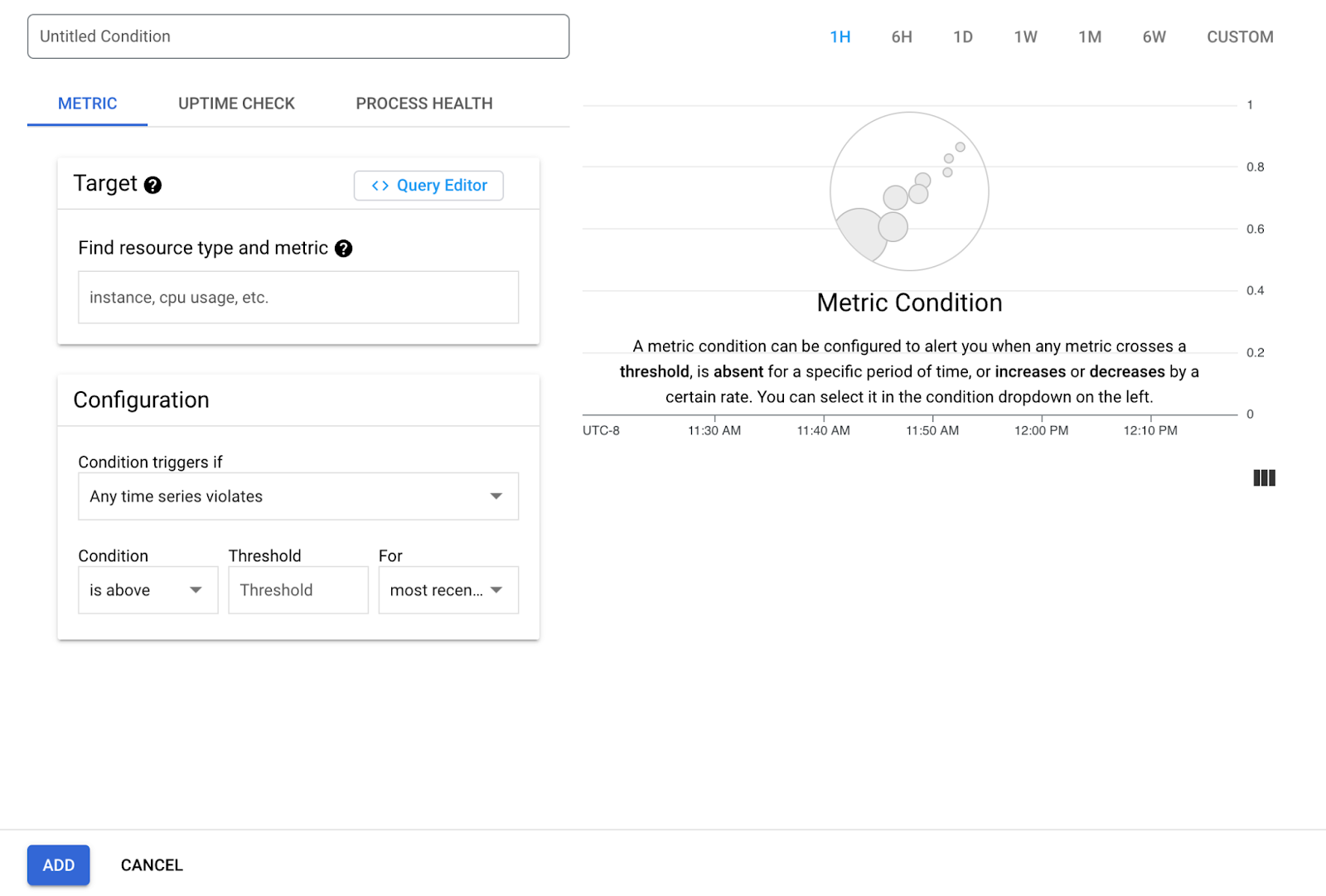
ターゲットには、前のセクションで説明した信頼度指標を選択します。この指標([詳細オプションを表示] > [アライナー])を使用して、アライナーがデルタに設定されていることを確認します。次の手順では、アラート条件を構成します。次の設定を使用します。
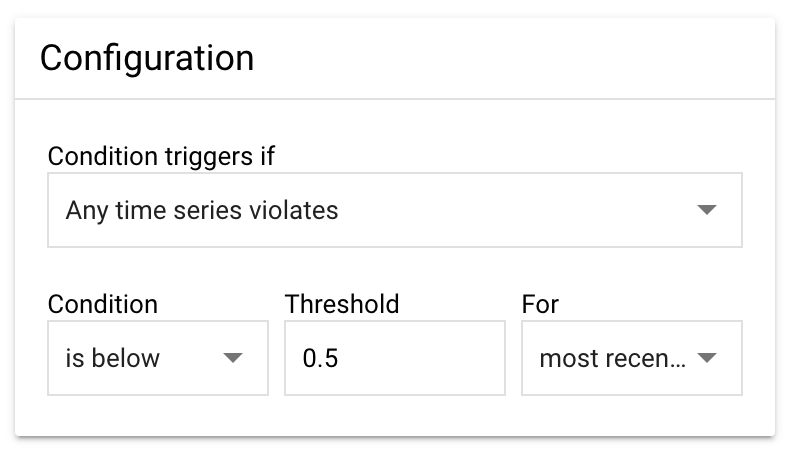
条件がトリガーされる場合 - アラートをトリガーするタイミングを決定するメインの構成です。[任意の時系列の違反] を選択します。これは、指標にしきい値を設定し、値がしきい値を超えたかどうかをモニタリングするためです。
条件 - 値がしきい値を下回ったときにアラートがトリガーされるように、[下回る] に設定します。この指標では、1.0 は統合が正常に機能していることを意味し、0.0 は明確な停止を示します。
しきい値 - この値が 0.5 に設定されている場合に最適な結果が得られるように、信頼度指標を作成しました。アラートの頻度を増やし、軽微なインシデントでも通知を受け取る場合は、この値を大きくします(最大 1.0)。その後、より重大な問題についてのみアラートを受け取るようにしたい場合は、この値を小さくしてみてください(最小値は 0.0)。
期間 - 停止がどのくらいの期間続いたらアラートを送信するかを指定する設定です。この設定は most recent value のままにして、しきい値を超えるポイントがあった場合にアラートを受け取ることをおすすめします。信頼度指標は 15 分ごとに公開され、その期間の平均成功率が確認できます。
条件の追加が完了したら、次のステップは通知チャンネルの選択です。最も簡単な通知方法はメール通知です。[通知チャンネル] プルダウンに表示されているメールアドレスを選択できます。
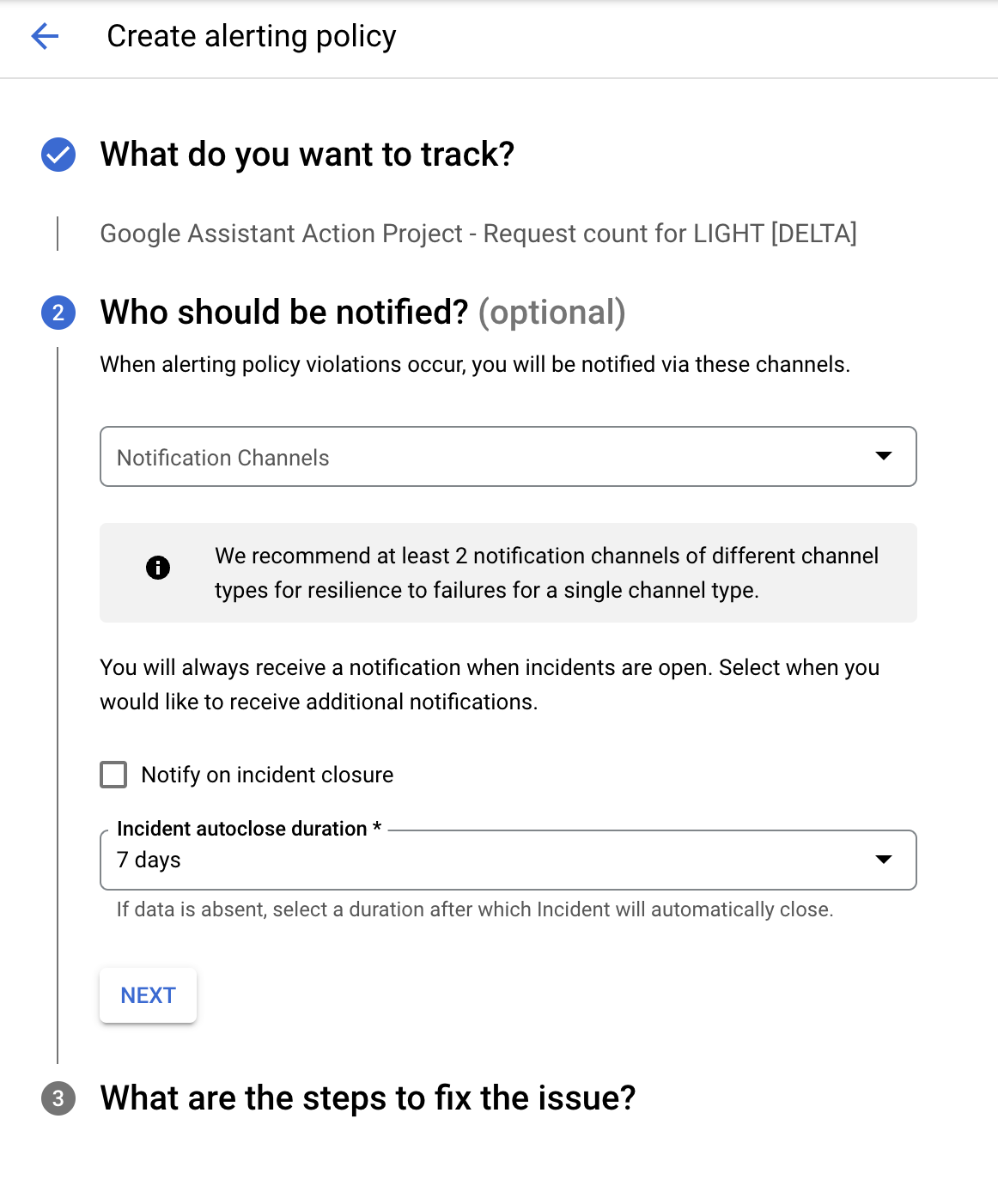
[Notify on incident closure] オプションをオンにすると、インシデントがクローズとしてマークされたときに別の通知が送信されます。その場合は、[インシデントの自動クローズ期間] も選択する必要があります。デフォルトでは 7 日間に設定されています。
最後の手順は、アラートに名前を付け、通知に含めるドキュメントを追加することです。
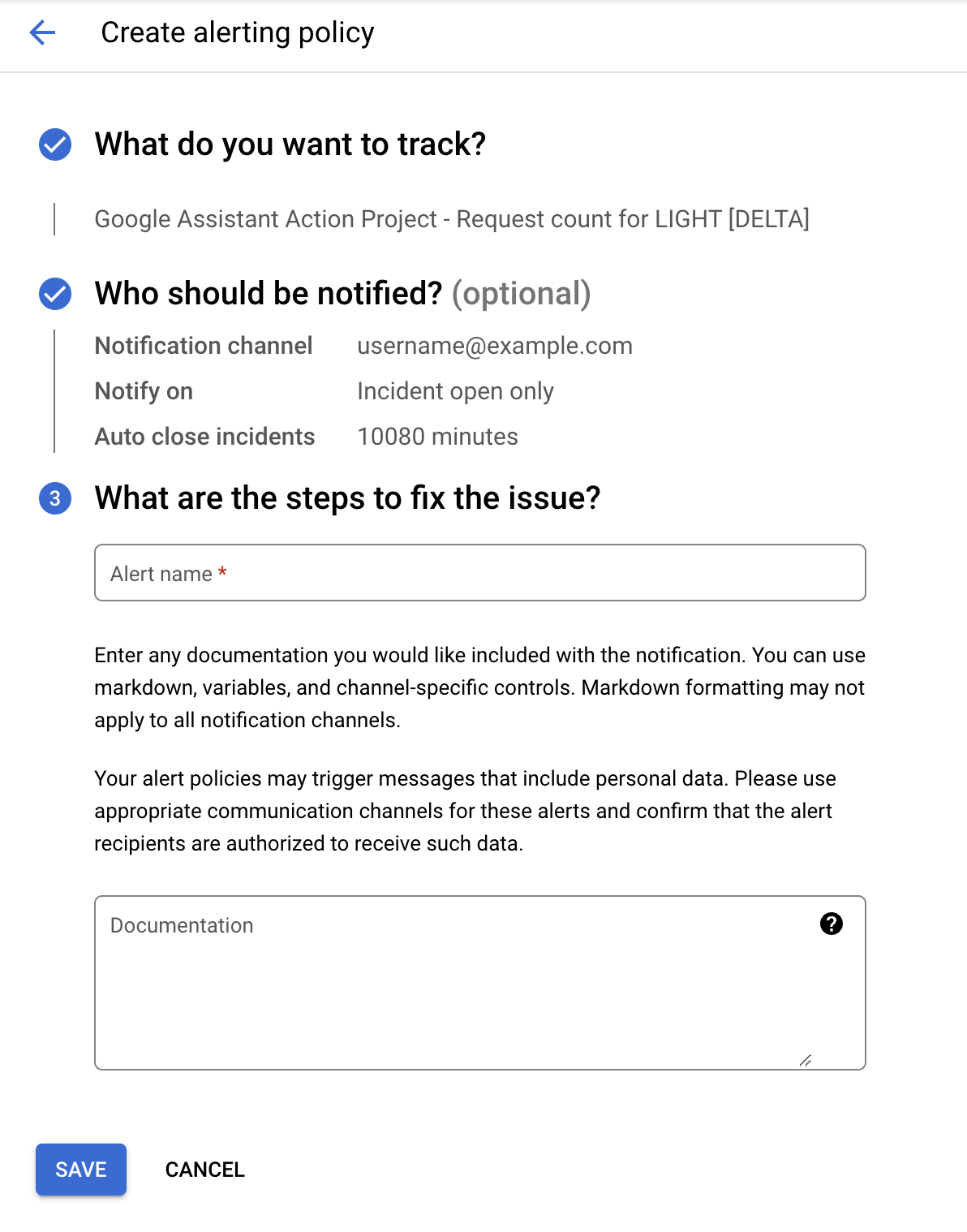
特にアラートを受け取るユーザーが自分ではない場合は、ドキュメントを提供することをおすすめします。インシデント発生時に確認する場所や、トリアージとデバッグの方法などの手順を追加すると、停止時に役立ちます。必要に応じて、トラブルシューティング ガイドを参照してください。
保存すると、アラート ポリシーが [アラート] ページの [ポリシー] セクションに表示されます。

5. サービス停止の軽減
アラートを設定すると、停止中に指定した通知チャネルから通知が届き、[アラート] ページにインシデント エントリが作成されます。
アラートの受信
この Codelab で提供したアラート チャンネルはメールでした。設定が完了すると、アラートは届かないはずです(停止が発生しないはずです)。ただし、アラートが届いた場合は、次のような通知が表示されます。
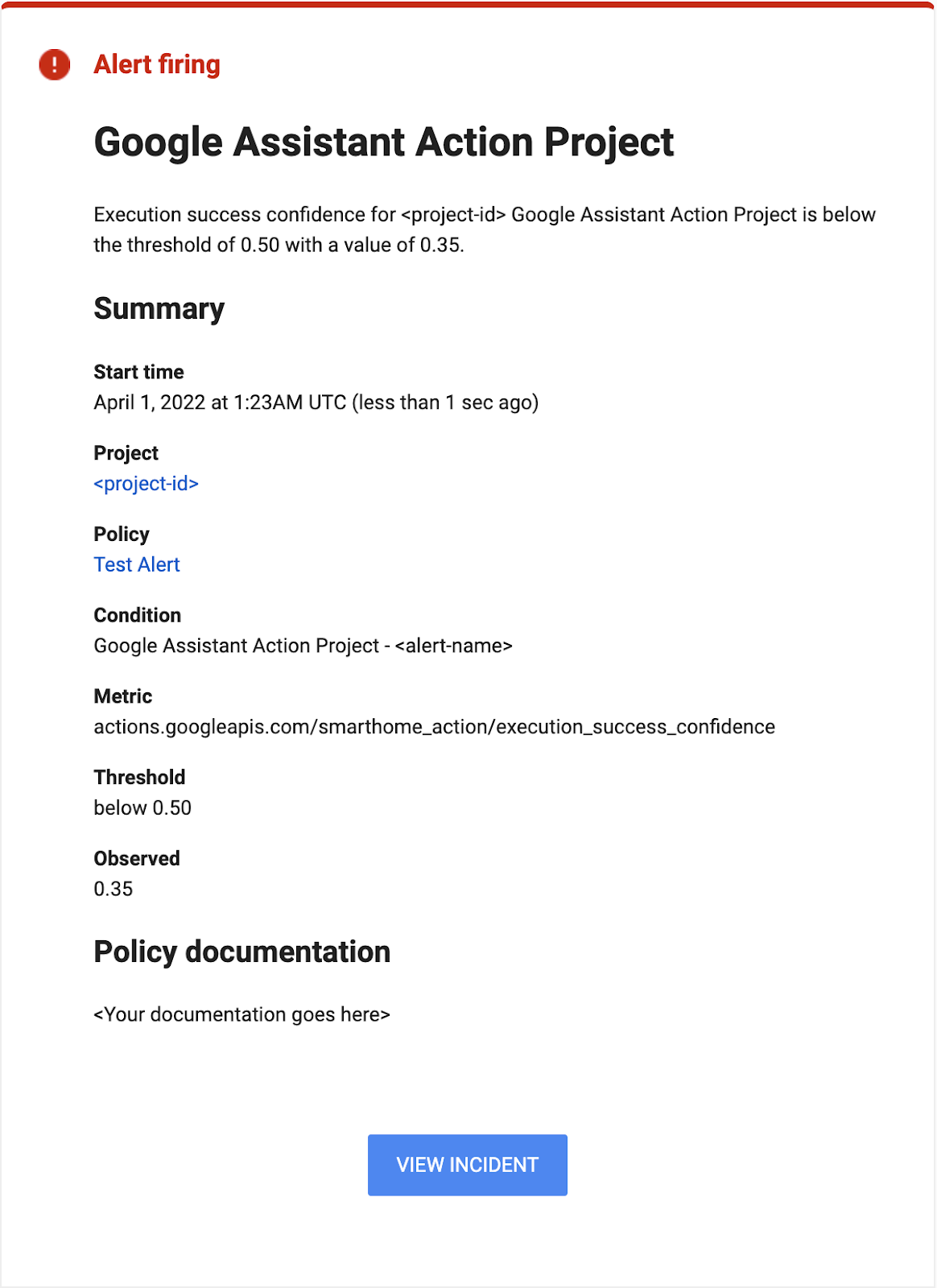
アラート通知には、指定したしきい値を超えた観測値と、インシデントが最初に開始されたときのタイムスタンプが表示されます。
モニタリング インシデント
インシデントが発生すると、[アラート] ページの [インシデント] セクションにもカウントされます。

特定のインシデントをクリックすると、停止の期間や重大度など、停止に関する詳細を確認できます。
アラートを受け取った場合は、まず指標を確認し、次にログで停止の原因となったエラーを検索することをおすすめします。これらの方法については、スマートホームをデバッグするの Codelab をご覧ください。
6. 完了
おめでとうございます!プロジェクトに提供された指標を使用してアラートを設定し、停止を自動的にモニタリングして、サービスの中断時に通知を受け取る方法を習得できました。
次のステップ
この Codelab で学んだことを活かして、追加リソースを参照しながら以下の演習に挑戦してみましょう。