
Cette suite de tableaux de bord et d'alertes vous aide à maintenir de manière proactive une intégration de haute qualité avec l'écosystème Google Home. Google s'engage à aider ses partenaires à développer un écosystème de haute qualité pour tous les clients.
Le tableau de bord comporte trois sections, chacune couvrant un élément clé qui contribue à la qualité d'une intégration globale.
Métriques Google vers partenaire : mesurent l'état des appels de Google vers votre backend cloud.
État du système : métriques partenaire vers Google : mesure l'état des appels de votre système vers Google.
État de l'appareil : précision de l'état : mesure la précision des états stockés dans les systèmes Google, qui sont utilisés pour répondre aux requêtes des utilisateurs.
Lorsque les métriques ne respectent pas leurs valeurs cibles, elles sont mises en évidence en rouge pour indiquer un problème susceptible d'avoir un impact sur l'expérience utilisateur. Les informations suivantes fournissent des détails sur chaque cible et expliquent pourquoi elle est importante pour vos utilisateurs.
Si le bouton suivant ne vous redirige pas directement vers le tableau de bord, vous pouvez y accéder en sélectionnant la page Présentation, puis Tableaux de bord. Ensuite, dans la liste Mes tableaux de bord, sélectionnez Tableau de bord des données vitales Google Home (Cloud) pour afficher votre tableau de bord.
Métriques Google pour les partenaires
La métrique Taux de réussite des requêtes/exécutions >= 99, 5% mesure la fréquence à laquelle les commandes des utilisateurs sont exécutées correctement.Elle permet d'éviter les réponses de l'Assistant telles que "Je n'arrive pas à accéder à l'appareil" ou la confirmation incorrecte d'une commande qui n'a pas encore été exécutée.
Qu'est-ce qu'un "succès" ?
Une transaction est marquée comme réussie si la plate-forme Google Home reçoit une réponse valide indiquant que l'action souhaitée a été effectuée ou que l'état demandé a été récupéré.
Les réponses qui incluent des exceptions non bloquantes (par exemple, un état SUCCESS accompagné d'une exception lowBattery) sont comptabilisées comme des transactions réussies.
La commande a atteint l'appareil et l'intention a été satisfaite malgré l'avertissement.
Qu'est-ce qu'un échec ?
Les erreurs listées dans Codes d'erreur courants de la plate-forme et marquées comme Action requise du partenaire sont considérées comme des "échecs" lors du calcul des taux de réussite des requêtes et des exécutions. De plus, les erreurs trouvées sur la page Erreurs et exceptions sont également considérées comme des "échecs", à l'exception des suivantes :
| Exceptions d'échec | ||
|---|---|---|
| aboveMaximumLightEffectsDuration | armLevelNeeded | inOffMode |
| alreadyArmed | bagFull | lockedToRange |
| alreadyAtMax | belowMinimumLightEffectsDuration | lowBattery |
| alreadyAtMin | binFull | maxSpeedReached |
| alreadyClosed | cancelArmingRestricted | minSpeedReached |
| alreadyDisarmed | deadBattery | notSupported |
| alreadyDocked | degreesOutOfRange | Hors connexion |
| alreadyInState | deviceJammingDetected | percentOutOfRange |
| alreadyLocked | deviceNotMounted | rangeTooClose |
| alreadyOff | deviceNotReady | relinkRequired |
| alreadyOn | deviceOffline | remoteSetDisabled |
| alreadyOpen | deviceTurnedOff | safetyShutOff |
| alreadyPaused | discreteOnlyOpenClose | targetAlreadyReached |
| alreadyStarted | functionNotSupported | tooManyFailedAttempts |
| alreadyStopped | inAutoMode | valueOutOfRange |
| alreadyUnlocked | inEcoMode |
La métrique Latence de requête/d'exécution (p90) <= 1 000 ms mesure le temps d'attente pour l'action demandée et permet de s'assurer que les utilisateurs n'ont pas à attendre trop longtemps (par exemple, quelques secondes pour que leur lumière s'éteigne).
Statistiques relatives à la latence
La latence est un indicateur essentiel de la réactivité de votre intégration pour l'utilisateur final. Le tableau de bord suit la latence du 90e centile (P90), qui représente l'expérience de vos utilisateurs les plus "lents" (par exemple, un P90 de 800 ms signifie que 90% des requêtes sont traitées en 800 ms ou moins).
Pour garantir la précision technique, Google mesure la latence différemment pour les vérifications de l'état et les commandes de l'appareil.
1. Latence des REQUÊTES (interrogative)
Cette métrique mesure le temps d'aller-retour Cloud-to-cloud lorsque Google demande l'état actuel d'un appareil.
- Début : Google envoie une requête
action.devices.QUERYà votre URL d'exécution. - Période de mesure : temps nécessaire à votre cloud pour recevoir, traiter et retransmettre la réponse HTTP complète à Google.
- Fin : Google reçoit et accuse réception de la charge utile de la réponse finale de votre service.
2. Latence EXECUTE (action)
Il s'agit du temps d'accusé de réception de la commande lorsque Google envoie une demande de contrôle à un appareil.
- Début : Google envoie une requête
action.devices.EXECUTEà votre URL d'exécution. - Période de mesure : temps nécessaire à votre cloud pour recevoir la commande et renvoyer une réponse d'accusé de réception.
- Fin : Google reçoit la réponse d'état
SUCCESS,PENDINGouOFFLINE. - Champ d'application technique : cette métrique mesure le temps d'accusé de réception de la réponse entre le cloud de Google et le vôtre. Il ne mesure pas le temps nécessaire au matériel physique (par exemple, une ampoule) pour effectuer le changement d'état physique, car cela implique souvent une latence du réseau maillé local en dehors du chemin cloud à cloud.
Répartition de la latence EXECUTE/QUERY
Lorsque vous analysez les codes temporels pour une latence EXECUTE ou QUERY, le délai aller-retour total peut être décomposé en flux séquentiel comme suit :
Étant donné que cette répartition compare les codes temporels côté Google et côté partenaire, les serveurs partenaires doivent être synchronisés avec le protocole NTP (Network Time Protocol). Même une légère dérive d'horloge (50 à 100 ms) faussera les délais d'acheminement calculés (t2 -
t1 et t4 - t3), ce qui peut entraîner des métriques logiquement impossibles, comme des latences de transit négatives.
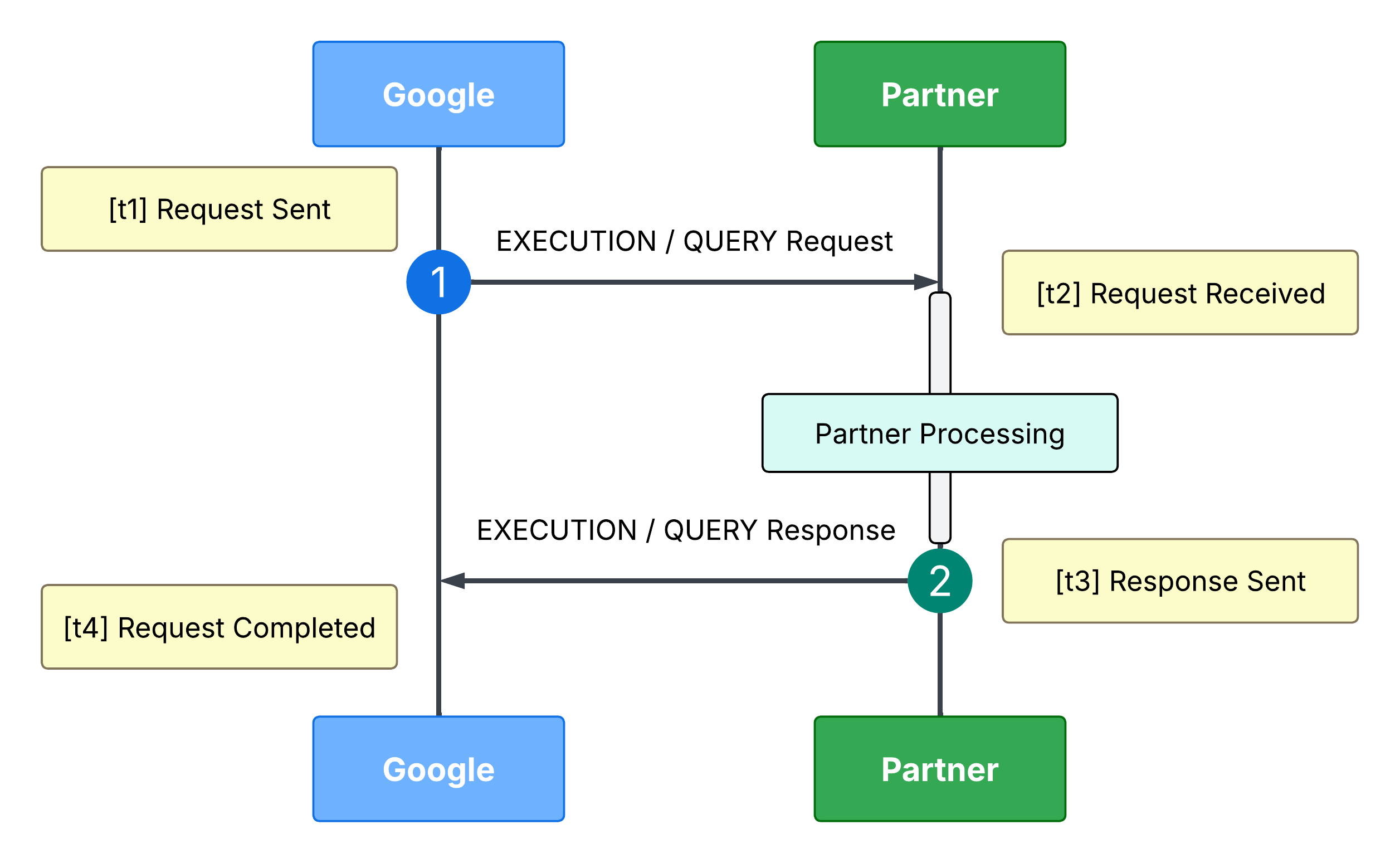
[t1] Demande envoyée (sortant Google) : Google lance la demande d'intention. Étant donné que t1 n'est pas directement exposé, il est calculé approximativement en soustrayant la latence totale du code temporel d'entrée final.
Temps de transit réseau (t1 à t2) : temps de transit réseau et temps d'attente estimés avant d'atteindre votre point de terminaison d'exécution.
[t2] Demande reçue (entrée partenaire) : code temporel exact de l'arrivée de la demande au niveau de la passerelle d'API ou du serveur d'entrée de votre environnement.
Traitement par le partenaire (t2 à t3) : latence d'exécution, de routage et de gestion des appareils en interne, entièrement dans votre environnement cloud.
[t3] Réponse envoyée (sortie partenaire) : code temporel indiquant le moment où votre service renvoie la réponse de fulfillment à Google.
Retour du transit (t3 vers t4) : temps nécessaire pour que le routage et la connexion réseau de retour soient effectués vers Google.
[t4] Demande finalisée (entrant Google) : Google reçoit et traite la réponse finale. Cet code temporel est explicitement enregistré dans vos journaux Google Cloud sous la forme receiveTimestamp.
Pour illustrer le lien entre ces métriques, prenons l'exemple d'une requête EXECUTE avec une latence totale enregistrée (latencyMsec) de 1 700 ms et un Google Cloud receiveTimestamp (t4) de 2026-05-25T15:25:00.550Z.
| Étape / Point de contrôle | Code temporel / Durée | Source et méthode de calcul |
|---|---|---|
[t1] Google Outbound |
15:24:58.850Z |
Calculé : t4 (.550Z) - 1700ms |
| Transit réseau | 150 ms | Dérivé : t2 – t1 |
[t2] Ingress pour les partenaires |
15:24:59.000Z |
Observé : enregistré dans les journaux de la passerelle partenaire |
| Traitement par les partenaires | 1 300 ms | Dérivé : t3 – t2 (votre temps d'exécution interne) |
[t3] Sortie partenaire |
15:25:00.300Z |
Observé : enregistré dans les journaux de sortie des partenaires |
| Retour en transports en commun | 250 ms | Dérivé : t4 – t3 |
[t4] Google Inbound |
15:25:00.550Z |
Observé : receiveTimestamp dans les journaux Google Cloud |
Options de réduction de la latence
Recommandations d'architecture pour le routage géographique
Si l'implémentation d'une adresse IP Anycast n'est pas possible, nous vous recommandons les alternatives économiques suivantes pour vous assurer que les utilisateurs sont desservis par le centre de données régional le plus proche.
Équilibrage de charge global (GLB)
Au lieu du routage statique, utilisez un équilibreur de charge d'application global (disponible auprès de la plupart des principaux fournisseurs de services cloud).
Fonctionnement : vous configurez un point d'entrée global unique (URL) situé à la périphérie du réseau. L'équilibreur de charge détecte automatiquement l'origine géographique de la requête à partir des clusters de traitement de Google et achemine le trafic vers le backend régional opérationnel le plus proche.
Avantage : Cette fonctionnalité offre les performances d'Anycast avec une complexité de configuration et des coûts considérablement réduits.
DNS tenant compte de la géolocalisation (GeoDNS)
Fonctionnement : configurez votre fournisseur DNS pour résoudre votre URL de traitement sur différentes adresses IP en fonction de l'emplacement géographique de la requête DNS.
Implémentation : assurez-vous que votre fournisseur DNS est optimisé pour les points de sortie de Google. Lorsque les services de traitement régionaux de Google (par exemple, aux États-Unis, dans l'UE ou en Asie) résolvent votre domaine, ils reçoivent l'adresse IP du centre de données dans cette région spécifique.
Stratégies d'optimisation au niveau de l'application
Au-delà du routage au niveau de l'infrastructure, vous pouvez implémenter les stratégies suivantes au niveau de l'application pour réduire la latence dans le traitement des requêtes.
Méthode de proxy "Trampoline"
Si vous devez conserver un centre de données principal, utilisez des serveurs proxy régionaux légers (Trampolines) pour gérer la première prise de contact.
Google accède à votre URL mondiale.
Un proxy régional (par exemple, une fonction Nginx ou Lambda légère) reçoit la requête.
Le proxy transfère la charge utile via votre backbone interne à haut débit vers la base de données principale.
Avantage : cela réduit le temps de "prise de contact TCP", qui est souvent le principal facteur de latence pour les requêtes longue distance.
Indication de région du jeton d'accès
Lors du processus d'association de compte (OAuth), votre système peut identifier la région de résidence de l'utilisateur.
Implémentation : encodez un identifiant de région dans le
access_tokenémis pour Google. Lorsque Google envoie une demande d'exécution, votre passerelle peut inspecter immédiatement le jeton et acheminer la demande vers le cluster régional approprié sans avoir besoin d'effectuer une recherche dans la base de données.
État du système : métriques "Partenaire vers Google"
Le maintien d'un taux de réussite supérieur ou égal à 99, 5% permet de s'assurer que les états des appareils sont corrects dans Google Home, que les appareils sont ajoutés et supprimés, que les automatisations se déclenchent et que les événements de l'historique s'affichent dans l'onglet "Activité" de Google Home app (GHA).
Le taux de réussite est calculé en fonction des codes de réponse HTTP renvoyés par Google lorsque votre cloud envoie des mises à jour d'état. Pour s'assurer que les partenaires ne sont pas pénalisés en cas de problèmes d'infrastructure côté Google, la métrique exclut les erreurs internes de Google du nombre d'échecs. Les appels d'API inclus dans le calcul se trouvent dans la documentation de référence de l'API HomeGraph.
Qu'est-ce qu'un "succès" ?
2xx (Succès) : la mise à jour de l'état a été reçue et traitée par Home Graph.
Qu'est-ce qu'un échec ?
Les erreurs 4xx (erreur du partenaire) représentent des échecs et indiquent un problème avec la requête envoyée depuis votre cloud. Voici quelques codes courants :
400 Requête incorrecte
Cause : le serveur n'a pas pu traiter la requête en raison d'une syntaxe non valide. Les causes courantes incluent un code JSON mal formé ou l'utilisation de la valeur "null" au lieu de "" pour une valeur de chaîne.
Solution : Assurez-vous que le corps de la requête est un fichier JSON valide (pas de structure incorrecte ni de valeurs nulles pour les champs de chaîne), et vérifiez que agentUserId correspond à la valeur de la réponse SYNC.
404 Not Found
Cause : deviceId ou agentUserId introuvable dans HomeGraph (pas encore synchronisé, déjà dissocié ou ID non correspondant).
Solution :
- Assurez-vous que
agentUserIdcorrespond à la valeur fournie dans votre réponse SYNC. - Utilisez l'API Home Graph SYNC pour déterminer si l'erreur 404 Not Found est due à un appareil ou à un utilisateur manquant dans HomeGraph.
- Veillez à déclencher
requestSyncaprès l'ajout, la suppression, le renommage ou la mise à jour d'un appareil ou d'un compte pour vous assurer que l'état reste à jour. - Gérez correctement les intents
DISCONNECTpour arrêter de signaler les appareils obsolètes. Après avoir reçu l'intentionDISCONNECT, votre service cloud doit cesser de publier les modifications sur Google avec Request Sync et Report State.
429 : Ressource épuisée
Cause : Votre intégration a dépassé le quota qui lui est alloué.
Solution : Consultez les instructions de la section "Étape 2a : Déboguer les problèmes de quota" du tableau de bord de gestion des quotas. Pour en savoir plus, vous pouvez également consulter Quotas et limites pour la maison connectée.
État de l'appareil : précision de l'état
Atteindre ou dépasser un taux de précision de l'état de 99,5% permet de garantir que les utilisateurs voient des résultats corrects lorsqu'ils consultent l'état des appareils ou utilisent des fonctionnalités d'IA comme Demander à Home. Si l'état est peu précis, il est possible que les automatisations ne se déclenchent pas et que les entrées d'historique n'apparaissent pas au bon moment dans l'onglet "Activité" de GHA. Pour en savoir plus, consultez État du rapport. Remarque : L'objectif de précision de l'état doit être atteint pour TOUS les traits compatibles.
1. Composants de précision
Cette métrique est dérivée d'échantillons pour lesquels Google peut vérifier l'état signalé par rapport à un résultat d'intention connu. Pour la précision technique, l'exactitude est évaluée selon deux voies distinctes :
- Précision basée sur les REQUÊTES : vérifiée lorsqu'un utilisateur ou un système interroge activement l'état actuel d'un appareil.
- Précision de l'EXÉCUTION : vérifiée en évaluant l'état de l'appareil après l'exécution de la commande, tel qu'indiqué après une demande de contrôle.
2. Métriques du tableau de bord (calcul horaire)
Le tableau de bord calcule la précision sur la base d'un intervalle d'une heure. Pour garantir la fiabilité statistique et éviter de pénaliser les intégrations présentant un bruit de signal faible, Google applique un seuil minimal de volume de trafic. Si une combinaison spécifique de trait et d'appareil accumule moins de 100 échantillons au total sur une période glissante de cinq jours, sa précision est considérée comme statistiquement insignifiante et est définie sur N/A.
Lorsqu'une heure présente un volume d'échantillons suffisant pour les deux chemins, la précision horaire de référence pour un état spécifique est calculée comme la moyenne des deux pourcentages indépendants :
Précision de l'état par heure = (Précision des requêtes % + Précision de l'exécution %) / 2
Chaque chemin d'accès est défini comme suit :
- Pourcentage de précision des requêtes = (Nombre d'échantillons précis de requêtes par heure) / (Nombre total d'échantillons de requêtes par heure)
- %d'exactitude de l'exécution = (Nombre d'échantillons exacts d'exécution par heure) / (Nombre total d'échantillons d'exécution par heure)
Score de précision des traits (calculé par trait) = SOMME(Exemples précis de requêtes + Exemples précis d'exécution) / SOMME(Nombre total d'exemples de requêtes + Nombre total d'exemples d'exécution)
Étant donné que le niveau de qualité évalue les performances minimales strictes dans votre écosystème, chaque caractéristique éligible et acceptée doit individuellement atteindre l'objectif de précision de l'état de >= 99,5% (il ne s'agit pas d'une moyenne entre les caractéristiques).
Cette vue empêche les appareils à volume élevé et à excellente précision de masquer les problèmes de justesse sur les appareils à volume plus faible. Les partenaires qui craignent que les caractéristiques sous-utilisées ne fassent baisser leur score peuvent être rassurés : une caractéristique rarement utilisée est automatiquement protégée par la vérification du volume de trafic minimal et ne sera pas prise en compte dans le score "Type et caractéristique les plus bas" à moins qu'elle ne réponde au seuil d'échantillon requis.
3. Améliorer la précision de l'état et de l'intégrité des appareils
Des écarts se produisent lorsque l'état stocké dans le Home Graph ne correspond pas aux résultats d'une REQUÊTE en temps réel.
Erreurs "Champ manquant"
Exemple DETAILED_ACCURACY_RESULT_QUERY_STATE_MISSING_FIELD
reportStateLog: { accuracy: "INACCURATE" agentId: "abc" detailedAccuracyResult: "DETAILED_ACCURACY_RESULT_QUERY_STATE_MISSING_FIELD" deviceId: "curtain" deviceType: "action.devices.types.CURTAIN" isMissingField: true isOffline: false queriedTime: "2026-04-13T12:20:26Z" queryReportStateDifferences: { queryState: "open_close { open_percent: 0.0 missing open_direction }" reportState: "open_close { open_state { open_percent: 100.0 open_direction: "LEFT" } }" } reportedTime: "2022-05-13T07:14:35Z" requestId: "123" result: "INACCURATE" snapshotTime: "2026-04-13T12:20:26Z" stateName: "open_state" traitName: "TRAIT_OPEN_CLOSE" }
Exemple DETAILED_ACCURACY_RESULT_REPORT_STATE_MISSING_FIELD
reportStateLog: { accuracy: "INACCURATE" agentId: "abc" detailedAccuracyResult: "DETAILED_ACCURACY_RESULT_REPORT_STATE_MISSING_FIELD" deviceId: "sensor" deviceType: "action.devices.types.SENSOR" isMissingField: true isOffline: false queriedTime: "2026-04-28T10:40:33Z" queryReportStateDifferences: { queryState: "temperature_setting { thermostat_mode: "off" thermostat_temperature_ambient: 20.0 active_thermostat_mode: "none" }" reportState: "temperature_setting { thermostat_mode: "off" active_thermostat_mode: "none" }" } reportedTime: "2024-09-20T15:00:00Z" requestId: "123" result: "INACCURATE" snapshotTime: "2026-04-28T10:40:33Z" stateName: "thermostat_temperature_ambient" traitName: "TRAIT_TEMPERATURE_SETTING" }
Cause : avec l'erreur DETAILED_ACCURACY_RESULT_QUERY_STATE_MISSING_FIELD ou DETAILED_ACCURACY_RESULT_REPORT_STATE_MISSING_FIELD, l'ensemble des champs de charge utile diffère entre votre réponse QUERY et votre requête Report State pour le même appareil.
Solution : Assurez-vous que la structure des données est identique dans les deux chemins d'accès. Si un trait est inclus dans SYNC, ses champs correspondants doivent être présents et cohérents dans les rapports proactifs et les requêtes réactives.
Erreurs "Inexact"
Exemple DETAILED_ACCURACY_RESULT_INACCURATE
reportStateLog: { accuracy: "INACCURATE" agentId: "abc" detailedAccuracyResult: "DETAILED_ACCURACY_RESULT_INACCURATE" deviceId: "outlet" deviceType: "action.devices.types.OUTLET" isMissingField: false isOffline: false queriedTime: "2026-04-12T16:02:58Z" queryReportStateDifferences: { queryState: "on_off { on: false }" reportState: "on_off { on: true }" } reportedTime: "2025-03-10T01:56:44Z" requestId: "abc" result: "INACCURATE" snapshotTime: "2026-04-12T16:02:58Z" stateName: "on" traitName: "TRAIT_ON_OFF" }
Cause : pour l'erreur DETAILED_ACCURACY_RESULT_INACCURATE, il existe une différence entre la valeur renvoyée dans la réponse QUERY et la dernière valeur de l'état du rapport.
Solution : Assurez-vous que l'état du rapport est déclenché chaque fois que l'état d'un appareil change, et que l'état du rapport et la requête fournissent toujours les mêmes valeurs à jour et tous les champs requis pour maintenir la cohérence des données.
Exemple DETAILED_ACCURACY_RESULT_MISSING_REPORT_STATE
"reportStateLog": { "isMissingField": false, "snapshotTime": "2026-04-13T07:56:21Z", "traitName": "TRAIT_ON_OFF", "detailedAccuracyResult": "DETAILED_ACCURACY_RESULT_MISSING_REPORT_STATE", "executionReportStateDifferences": { "expectedPostExecutionDeviceState": { "onOff": { "on": false } }, "preExecutionDeviceState": { "onOff": { "on": true } }, "executionCommand": { "requestId": "test001", "beginTimestamp": "2026-04-13T07:56:20Z", "action": { "trait": "TRAIT_ON_OFF", "actionType": "ONOFF_OFF" }, "status": { "statusType": "SUCCESS_STATUS" }, "endTimestamp": "2026-04-13T07:56:21Z", "executionType": "PARTNER_CLOUD" }, "reportState": {} }, "accuracy": "MISSING_REPORT_STATE", "deviceType": "action.devices.types.LIGHT", "agentId": "abc", "stateName": "on", "result": "MISSING_REPORT_STATE" }
Cause : avec l'erreur DETAILED_ACCURACY_RESULT_MISSING_REPORT_STATE, le partenaire a exécuté la commande avec succès, mais n'a pas renvoyé l'état de l'appareil mis à jour à Google.
Solution : Envoyez toujours une mise à jour Report State après l'exécution d'une commande afin que HomeGraph reçoive le nouvel état de l'appareil.
Exemple de DETAILED_ACCURACY_RESULT_NO_STATE_REPORTED
eportStateLog: { accuracy: "INACCURATE" agentId: "abc" detailedAccuracyResult: "DETAILED_ACCURACY_RESULT_NO_STATE_REPORTED" deviceId: "switch" deviceType: "action.devices.types.SWITCH" isMissingField: false isOffline: true queriedTime: "2026-04-13T13:53:26Z" queryReportStateDifferences: { queryState: "online { online: false } " reportState: "" } reportedTime: "1970-01-01T00:00:00Z" requestId: "test001" result: "INACCURATE" snapshotTime: "2026-04-13T13:53:26Z" stateName: "online" traitName: "TRAIT_ONLINE" }
Cause : Pour l'erreur DETAILED_ACCURACY_RESULT_NO_STATE_REPORTED, aucun état n'a été reçu pour cet appareil (l'état est vide et le code temporel indiqué est à l'époque), malgré les résultats de la requête qui fournissent l'état actuel.
Cela indique que les mises à jour de l'état ne sont pas déclenchées, qu'elles n'atteignent pas HomeGraph ou que l'appareil ne signale pas correctement les transitions de son état de connectivité ou de fonctionnement.
Solution : Assurez-vous que l'état du rapport est déclenché et envoyé correctement pour tous les changements d'état. Vérifiez que la logique du backend gère correctement les mises à jour de l'état, confirme la réussite de la diffusion à Google HomeGraph et garantit que l'appareil synchronise constamment son état pour que l'interface utilisateur et le moteur d'automatisation soient précis.